


The topic of authentication/authorization is one of those things that all engineers come in contact with at some point but quickly forget.
Unless you work at an Auth company or find yourself in a dedicated auth role, this is a topic that you learn one week, implement the next, and forget about for months.
Lucky for us, there are now plenty of offerings that make these flows easier to implement:
- Managed auth companies like Auth0 and Clerk
- Open-source libraries like Lucia, Auth.js, and Passport in JS ecosystem, Devise in Rails, and starter kits like Breeze in Laravel
But sometimes, it's nice to look under the hood and see what's going on.
So in this post, I'm going to attempt to give us all a refresher on OAuth 2.0, explore some common "flows", and do a deep dive into "client vs server-side auth" in the context of the OAuth 2.0 protocol.
Let's dive in.
An OAuth 2.0 Primer
If you're like me, you probably have a good conceptual idea of what OAuth 2.0 is, but might have a hard time explaining the technical details.
"It's that thing that allows you to sign in with Google, Facebook, or Apple"
While a simple construct, there are many layers of implementation details.
OAuth 2.0 in 30 Seconds
OAuth 2.0 is an industry-standard authorization framework maintained by the IETF (Internet Engineering Task Force) that defines all the specifications for enabling 3rd party applications to obtain limited access to an HTTP service. This includes, but is not limited to definitions for:
- "Flows" (also called "Grant Types")
- Required endpoints to be implemented by an auth server (e.g.
/authorize,/token, etc.) - Security considerations
Essentially, it defines how an application should implement a feature like "Login with Google".
Authentication vs. Authorization
First, we need to review the differences between authentication and authorization. To keep this high level, here are some key differences to remember:
- Authentication is about "who"
- Identify user with credentials (username, password, etc.)
- ID Token with claims through the OpenID Connect Protocol (OIDC)
- Authorization is about "what"
- What can the user see or interact within the system?
- Access token via OAuth 2.0 protocol
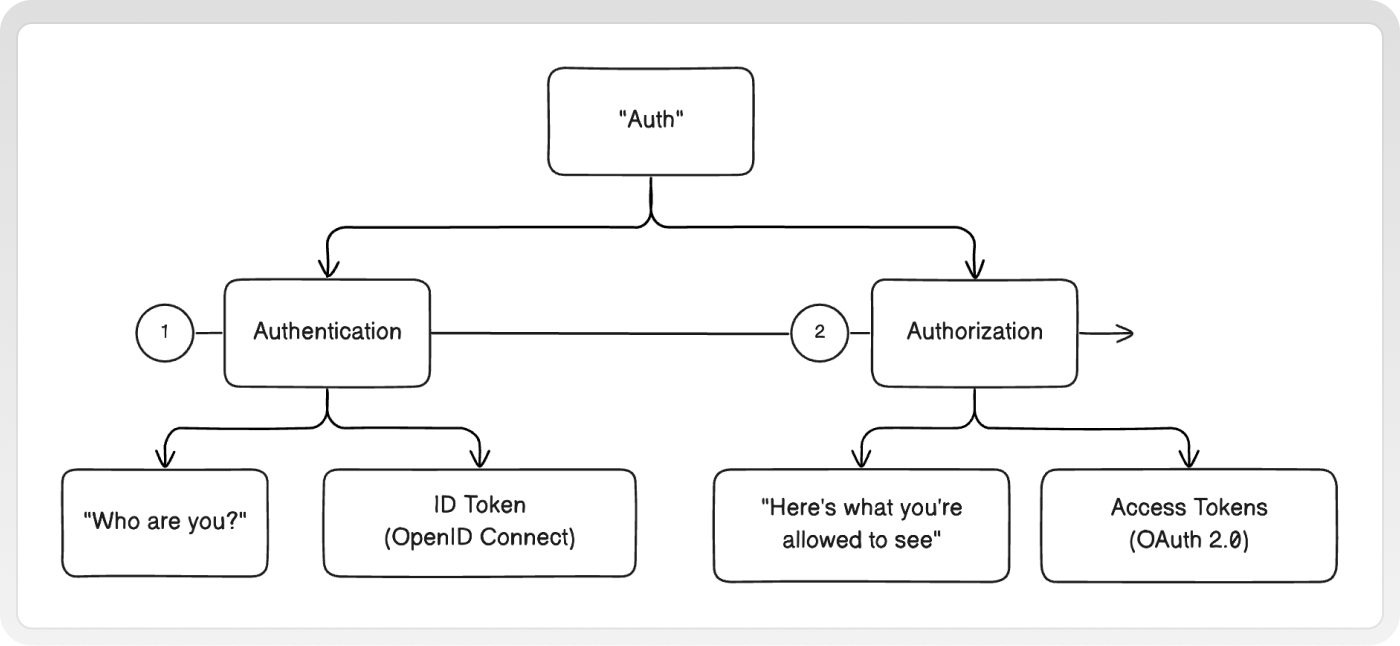
You'll notice in the diagram that authentication and authorization is a sequential, not parallel process. We first must authenticate and only then can we know what to authorize.
Basic OAuth 2.0 Terminology
As a brief refresher, here are some terms to remember:
- Client App: is the app requesting access to a protected resource (e.g. "Login with Google")
- Resource Owner: is typically the end user (human) granting "client" access to protected resources (e.g. "Yes, you can access my Google profile info")
- Resource Server: the server who has protected resources (and requires an access token to get those resources)
- Authorization Server: the server who authenticates ("who") and grants an access token ("what") to the "resource owner"
- Grant Types ("Flows"): these are standardized flows that specify how the access token is retrieved. You can read more about all the different grant types here, but below are the most common:
- Authorization Code - commonly known as "server-side auth"
- Authorization Code with PKCE - commonly known as "client-side auth"
- Other flows include "Client Credentials" (machine-to-machine apps), "Device Code" (i.e. Apple TV), and several legacy flows like "Implicit Flow" and "Password Grant"
What is OIDC (OpenID Connect)?
OIDC is a separate protocol from OAuth 2.0 that is solely responsible for authentication. In other words, OIDC + OAuth 2.0 are complementary protocols that fit into the broader topic of "Auth".
OIDC is "authentication" (also referred to as AuthN).
OAuth 2.0 is "authorization" (also referred to as AuthZ).
In the diagrams below, the "Login" step is where OIDC happens, but I have abstracted many of the implementation details away so we can focus on the differences between client and server-side auth.
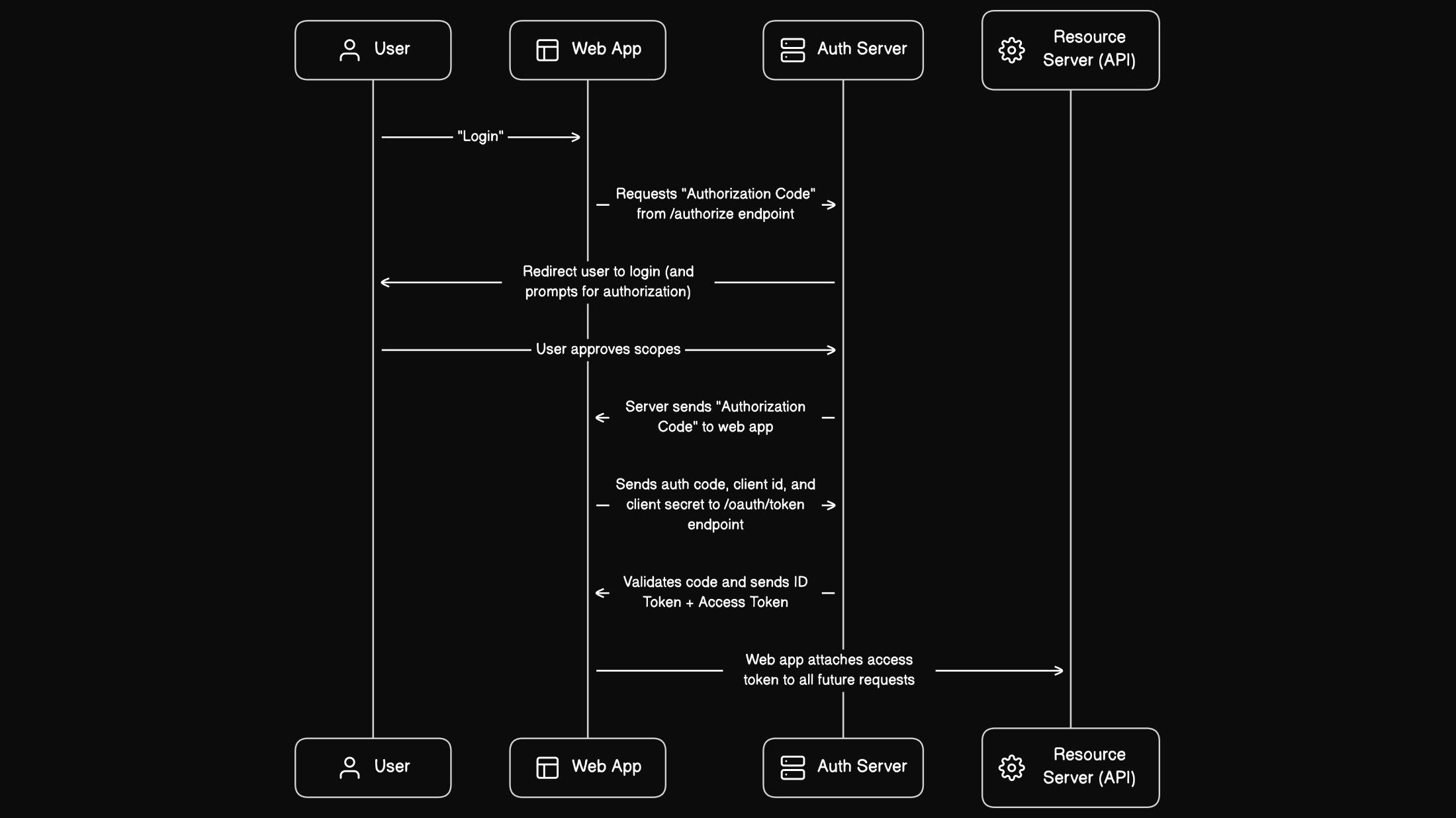
Authorization Code Flow (server-side)
Authorization code flow is the most common server-side OAuth 2.0 flow you'll see in web applications. The basic premise of this flow is:
- App opens browser, sends user to the auth server (e.g. "Login with Google")
- User logs in (the OIDC step), sees authorization prompt (e.g. "Can we access your Google profile"), and approves the request
- Auth server redirects to the "callback URL" of the application with an "authorization code" as a query string parameter
- App reads the query param, sends that auth code back to the auth server along with a client id and secret, and in exchange, receives an ID and access token.
- App can now attach the access token to future requests
You can see the flow in the diagram below:
.png)
Below, I'll walk through some of the considerations a developer must make when implementing a server-side auth flow like Authorization Code Flow.
Server-Side Simplicity
As shown in the diagram above, Authorization Code Flow happens primarily between two servers (your web server and the auth server). This keeps the overall flow simpler for a couple of reasons.
First, this means we can store the client secret directly on the server in an environment variable. As you will see in the next section, this is not possible for client-side auth and requires a significant bundle of JavaScript to generate and secure the client "secret".
Second, by using a server-side flow, auth states will be available prior to rendering your UI. This generally results in simple, maintainable auth checks. For example, here's a sample implementation using the Next.js app router:
While this simplicity is great, it means that to transition auth states, a full page reload is required. For most apps, this is a fine tradeoff and it comes with the added bonus of keeping auth states consistent across browser tabs!
Provides Centralized Control
Server-side auth is generally easier to secure and comes with more control for the organization. Generally, when working with an OAuth 2.0 flow, the auth server is separate from the web server and the security of the auth server is abstracted away and managed by another company like Auth0.
That said, regardless of whether you're managing your own auth server or outsourcing that function, doing things server-side comes with many benefits:
- Servers can be equipped with firewalls, intrusion detection systems, and other security controls
- Server security patches and updates can be applied quickly
- User sessions are managed server-side by the organization, which means they can be invalidated or terminated based on suspicious activity
- All communication between the web server and the auth server happen server-side, which eliminates client-side vulnerabilities (i.e. XSS attacks)
That said, it does not come without risks and overhead. When dealing with server-side auth, it is important to consider:
- A centralized server is a single point of attack, so configuring the server properly to encrypt data in-transit, use strong hashing algorithms, use http-only cookies to protect sessions, and regularly audit the server for compliance is important.
- Server-side auth is still vulnerable to CSRF (cross site request forgery) and DDoS attacks, so proper rate-limiting and anti-CSRF tokens are required.
In most cases, the centralized control + simplicity is a security benefit and is why server-side auth is often considered more secure than client-side auth.
What about serverless?
Before I go any further, I want to clarify that the "server-side auth" we're talking about here is specifically referring to Authorization Code Flow with "token based authentication" (i.e. JWTs). OAuth 2.0 does not mandate the use of JWTs as a token format, but this format is very common and works well with serverless architectures.
Since a JWT is stateless, it can be stored in an encrypted cookie and delivered with each request, thus making Authorization Code Flow highly compatible with both traditional and serverless architectures as it doesn't require an external session store.
In a more traditional session-based auth scheme, serverless architectures would require external KV stores like Redis to maintain auth state.
When to use Authorization Code Flow
Due to the simplicity and great developer experience, Authorization Code Flow is always a great choice for web applications if your architecture permits it. Any web app executing on the server is a good candidate for this flow.
Using Authorization Code Flow server-side is generally NOT suitable for:
- SPAs
- Native Apps
"Public Clients" like SPAs and native apps are typically not a great fit for a server-side Authorization Code Flow for one reason—they cannot store the client secret securely.
For a server-side OAuth 2.0 flow, both a client ID and client secret are required to identify an app to the auth server (i.e. Auth0 servers). With an SPA, the client-side bundle can be inspected while a Native App can be decompiled. In both cases, the secret would be exposed—a big problem from a security standpoint.
While both of these apps interact with servers in various capacities, their API requests are not tied to page loads like a traditional server-side app, which makes them a bad fit for the server-side auth model. Maintaining a server-side session would require page reloads and defeat the purpose of the SPA model.
Instead, these types of apps would benefit from a slight modification to Authorization Code Flow where the client is responsible for dynamically generating the secret that is used for authorization.
Authorization Code Flow + PKCE (client-side)
In cases where the app is a public client (SPA, native), we can use an extension to Authorization Code Flow called "Proof Key for Code Exchange" or PKCE (pronounced "pixie"). The total flow is often referred to as "Authorization Code Flow with PKCE".
The flow is similar to the server-side flow with two major differences:
- The client "secret" (code challenge and verifier) is dynamically generated by the client rather than stored on the server
- The client interacts directly with the auth server rather than delegating that function to the server-side web app. A "session" is still maintained, but this is handled by the auth server rather than your own server.
.png)
More Complex, Harder to Secure
Moving from regular Authorization Code Flow to Authorization Code Flow + PKCE requires a significant increase in complexity and code surface area to properly secure.
Since the client secret isn't stored on the server, the client app must generate it "on the fly" and manage the lifecycle of securely storing, refreshing, and rotating the obtained access token.
Before hitting the auth server, the client (browser) will generate a "code challenge". This consists of two steps:
- Generate a cryptographically random string called
code_verifier - Pass
code_verifierinto a hash function, most oftencode_challenge = SHA256(code_verifier)
The auth server will later use the specified method (e.g. S256) and the code_verifier to recreate and validate the code_challenge value.
This code challenge step is required since the SPA cannot store (and send) a client secret along with the Authorization Code (as we did in the basic Authorization Code Flow).
In addition to the code challenge, the way we persist the "session" has to change too.
In short, it becomes a lot more complex.
From a user experience perspective, we don't want the user to re-authenticate every time they refresh their browser. Likewise, we also don't want to store access tokens in the browser for the risk of XSS attacks (e.g. hacker injects a script that reads local storage, grabs the access token, and now can use it however they like).
To address these challenges, open-source libraries like Auth0 SPA JS have been created.
Without going into too much detail, this library uses a method called getTokenSilently which either uses refresh tokens (if enabled) or a cookie-based session (in conjunction with hidden iframes) established between the client (browser) and auth server that allows the client to dynamically fetch an access token without re-authenticating each time. It's not what I would call "light reading", but here's where all of that magic is happening if you'd like to dig through the code.
And thanks to a growing number of browser privacy features like Intelligent Tracking Prevention (in Safari) that aggressively block 3rd-party cookies, the cookie used to maintain the session with the auth server may be blocked or expiry length shortened. The only way to combat this is by using refresh tokens alongside refresh token rotation.
Smoother UX, but more Error-Prone
SPAs and Native apps, both great candidates for client-side auth are known for their smooth, seamless client-side experiences.
Unlike the server-side auth scenario, these apps manage auth state directly in the browser (or on the device) and can seamlessly transition auth states without a page reload.
As you can imagine, this comes with tradeoffs.
More Boilerplate
First, client-side auth requires a bit more boilerplate because we won't know the auth state until the auth request is made from the browser. This requires us to check for loading and error states in addition to the auth state. Take a React app for example:
Maintaining State Across Browser Tabs
Not only that, but with all this added boilerplate, it increases the surface area for auth-related bugs.
One particular area that can be challenging is maintaining the auth state across browser tabs. In a traditional server-side auth scenario, the auth state remains in-sync across tabs because its lifecycle is tied to page reloads. With client-side auth, a few bad useState implementations can cause one tab to be "logged in" while another tab is "logged out".
When to use Authorization Code with PKCE
Due to its added complexity, it is generally preferable to avoid client-side auth like PKCE unless you are developing an application that has no other option (SPAs, Native Apps, some IoT devices). Authorization Code + PKCE is the current "best practice" for these types of apps.
Thanks to the PKCE extension specification alongside maturing client-side libraries like Auth0 SPA JS, implementing client-side auth is becoming easier and more secure to use. But as with all abstractions, the hidden complexity isn't always as hidden as we'd like.
TL;DR
So there you have it! A refresher of OAuth 2.0 and an overview of the two main strategies for authenticating and authorizing users in various types of web apps.
As a quick recap, here's what we learned:
- What is OAuth 2.0?: OAuth 2.0 is the "spec" that defines various "flows" for 3rd party apps to obtain access tokens which allow them to access protected resources from an HTTP service
- Authentication vs. Authorization: Authentication is all about usernames, passwords, and "who" the user is. Authorization is about "what" they have authorization to read, create, update, and delete.
- Common auth flows: The most common flow is Authorization Code which we can add PKCE to for SPA and native apps. Other common flows include "Client Credentials" (machine-to-machine), "Device Code" (Apple TV, etc.). Legacy flows include "Implicit Flow" (PKCE's predecessor) and "Password Grant" (simple username + password)
- Authorization Code Flow (server-side) vs. Authorization Code Flow with PKCE (client-side): In general, server-side auth is simpler to implement, more secure, and provides a better developer experience, but can be a slight sacrifice in end-user experience. Client-side auth (in theory) wins from a user experience standpoint, but is more complex and thus, more prone to security issues and bugs.
- Use Authorization Code Flow by default, add PKCE for SPAs and Native Apps
- Takeaways: While "Auth" as a topic may appear to be simple, it is far from it. There are many layers of abstraction required to securely authenticate and authorize a user in a web app and learning what's going on under the surface can be helpful in determining what type of auth to use and how to implement it correctly.

.svg)
.svg)
.svg)
